How Adopting Site Reliability Engineering Transforms Your Digital Infrastructure into a Reliability Powerhouse

CTO
Hi friends, today the MadAppGang team is sharing our experience with Site Reliability Engineering (SRE) — a useful tool for all developers.
Specifically, we’re discussing how SRE is applied in software development and the practices that help us overcome challenges.
Ask any developer "What do you like most about your job?", and very often the answer is "I like solving problems."
We’re no exception. We see problems and look for ways to solve them everywhere, including problems affecting productivity and speed.
From small projects to significant challenges
We’ve been developing apps for years, and we've had a lot of practice building quality products.
But like many of you, we’ve run into problems when small projects started to grow very fast. We were eager to deliver new features as quickly as possible, but we also accumulated technical debt. Our flexibility and confidence in delivering the product began to diminish over time.
As we learned more about SRE, we realised that many of these problems could be solved by adopting SRE principles.
Let's take a look at some of the most common challenges, maybe you've faced or are facing these challenges right now.
1. Problems with continuous integration processes

As our teams continued to grow, so did the volume of code changes. We had implemented parallel execution in our continuous integration (CI) pipeline but knew our testing practices could benefit from optimisation.
Even with parallel execution, our tests were consuming 20 to 30 minutes of valuable time. This resulted in frustrating delays in critical change deployments.
To illustrate, let’s say a team of developers works on a web application. As the team grows rapidly, it makes numerous changes to the code daily.
Long test execution times in the CI pipeline mean each code change takes up to 30 minutes to integrate. This delay hampers the developers’ ability to quickly introduce new features and enhancements, frustrating both the development team and end users.
Check out a clever solution on how to speed up your Docker build from minutes to seconds from MadAppGang's CTO, Jack Rudenko.
2. Bug accumulation

Our team often found itself caught between fixing less critical bugs and focusing on developing new features. The natural inclination was to prioritise features, leading to a gradual accumulation of unresolved bugs.
The challenge then became determining which lingering issues needed immediate attention and which could be temporarily sidelined.
Imagine a mobile app development team striving to release new features and updates quickly. But they face a dilemma: a backlog of reported bugs, some minor cosmetic issues, and other functional defects.
To meet tight deadlines, the team decides to focus on developing new features, leaving the bug backlog untouched. Over time, the bug backlog grows, and the team is faced with deciding which bugs to prioritise and which to postpone.
3. Doubts about deploying new functionality
On one app project, we faced a significant obstacle: low test coverage, particularly within the legacy code base. We had limited confidence in making changes to legacy code because of the fear of unexpected side effects. The lack of comprehensive test coverage hindered our ability to ensure a smooth deployment process.
To give you a better understanding of the problem, here’s an example: a software company maintains an aging desktop application. The company is working to introduce modern features and enhancements, but a significant portion of the app’s code base consists of legacy code.
This legacy code lacks comprehensive test coverage, so the team is reluctant to make changes because they can't be sure how changes will affect other parts of the application. This uncertainty leads to delays in deploying new features and a reluctance to change the legacy code.
4. Loss of users

We noticed a worrying trend: some users were abandoning our application due to sluggish performance, thanks to lengthy external API calls. However, we lacked the data to fully understand the extent of user attrition and the underlying reasons.
Picture an e-commerce platform reliant on external APIs to retrieve product information. Users frequently complain about slow page load times, especially when viewing product details. Many users abandon their shopping sessions because they’re frustrated with the delays.
The development team suspects that lengthy API calls are the cause, but lack detailed data on the number of users affected and specific performance bottlenecks. This lack of information hinders their ability to make targeted improvements and retain users.
Steps to success: How SRE enhanced our development
How did SRE help us address these issues? Let's look at some of the steps:
1. Measuring SLIs and SLOs
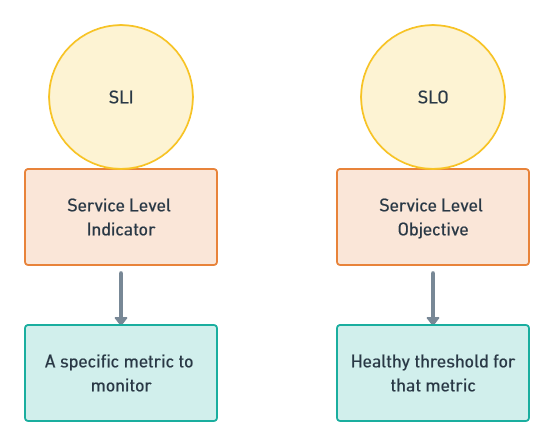
We started by measuring the reliability of our application by defining Service Level Indicators (SLIs) and Service Level Objectives (SLOs). These metrics gave us clear availability data for users.
As an example, let’s look at developing a mobile ride-share app. We can define an SLI that measures the percentage of ride requests completed within 5 minutes. The associated SLO states that 98% of ride requests must meet this criterion. By continuously tracking this SLI against the SLO, the team has insight into the app's performance.
If the SLI shows that the app consistently fails to meet the SLO, we can conduct a deeper analysis. This involves looking at factors such as server response time, network latency, and concurrent user activity that could affect ride request response times.
By proactively addressing SLO deviations, we can maintain a high level of service reliability and users can expect fast and convenient travel.
2. Establish error budgets

Error budgets help us understand how much the application could deviate from expected values.
A good example is a cloud-based document collaboration platform, and the error budget is the number of document synchronisation errors.
The team agrees that no more than 0.5% of document sync requests monthly should result in errors. If the error rate exceeds this threshold, the team temporarily pauses the addition of new features until the synchronisation issue is resolved.
This approach ensures that users get seamless document sharing and editing.
3. Customise alerts
We created alerts that made us aware of problems but didn't clog our inboxes with unnecessary notifications.
We followed the example of a cloud hosting provider. Instead of sending alerts for every minor server fluctuation, the team configured its alert system to only send alerts when the server's CPU usage exceeded 90% for more than 10 minutes.
This approach ensured that the operations team only received alerts when there was a persistent and potentially critical problem, allowing them to respond quickly.
4. Test rework

In our quest for more efficient development, we overhauled our testing approach to achieve two critical goals: reducing continuous integration times and increasing deployment confidence.
For web development, we streamlined our extensive test suite to focus on core functionality. This optimisation significantly reduced CI times, enabling faster updates and early detection of issues.
Similarly, in mobile app development, we fine-tuned testing around critical functions such as booking confirmations. This resulted in faster CI and increased confidence in the core functionality of our app.
These improvements meant we could respond quickly to user needs while maintaining high-quality standards in both web and mobile development.
5. Implementation of Canary Releases
We implemented a Canary Release mechanism that allowed us to test a new version of the application on a limited audience before full deployment.
Here's how we rolled out the new version of our ride-sharing mobile app. Our development team first released it to a small percentage of users in specific geographic regions. These "canary" users provided feedback on the app's performance, usability, and potential bugs.
If the feedback is positive, the new version is gradually made available to all users. This phased approach minimises the risk of widespread problems and ensures a smooth transition to the updated application for all users.
6. Using Terraform

Managing the deployment of cloud infrastructure is a critical aspect of SRE. One of the best tools for this is HashiCorp Terraform.
It's the tool we chose to automate the provisioning and configuration of the cloud infrastructure for all of our projects, for example, Chubby Dog. We use the most innovative tools from the AWS cloud to deliver the most technically innovative and cost-effective solutions.
Terraform provides efficient, scalable, and reliable infrastructure management. It provides a declarative approach to infrastructure provisioning, multi-cloud support, automation, consistency, version control, modules, and scalability.
We’ve made continuous integration much easier for ourselves and want to share with you our experience and a simple algorithm with 8 easy steps to deploy a complete infrastructure. We’re sure you’ll find them useful.
It's very convenient that you don't have to manually create instances, networks, and so on in the cloud provider's console. For us, it was enough to write a configuration of 40 lines of code. It defines how we see our infrastructure.
Terraform maps the resources defined in the configuration file to the corresponding cloud provider resources. If differences are found, a plan is generated. This is a list of changes required to make the cloud provider resources match the actual configuration specified in your configuration file.
Terraform automatically implements these changes by making the appropriate calls to the cloud provider.
One of Terraform’s best features is its quick disaster recovery. We love it! Additionally, it’s noteworthy that we have implemented SRE practices into our Terraform scripts. Our infrastructure benefits from robust monitoring and observability features through the integration with AWS CloudWatch, AWS XRay, and AWS ECS.
This strategic incorporation of SRE principles enhances the reliability, scalability, and overall performance of our systems, ensuring a more resilient and efficient environment for our operations.
Another benefit is that this configuration is created in human-readable text format. This makes it very easy for any developer to read and understand what the infrastructure is. Our infrastructure management files and assets are in Git. Using it to manage your infrastructure allows:
- CI/CD for infrastructure delivery
- track history changes
- read diffs
- initiate pull requests
- you to easily roll back to previous states.

The SRE way to brighten your day
All these steps helped us improve the quality of our products, increase deployment confidence, and reduce risk.
We believe that applying the principles of SRE can make your code development more enjoyable and efficient. Don't forget that "SRE is what happens when you ask a Software Engineer to design an operations team." (Google SRE Book).
Need help getting your project's development back on track? Get in touch with us today.

