Navigating modern CI/CD: Strategies and platforms for efficient development and deployment

CEO
Gone are the days when software development was a quick iteration over many months without the ability to make frequent updates. In today's dynamic software development environment, market demands change constantly and competition is fierce. Efficiency and delivering new features quickly are now critical success factors. This is where Continuous Integration (CI) and Continuous Deployment (CD) methodologies come in, revolutionising how software is developed and deployed.
What are the magic acronyms CI/CD?
Continuous Integration and Continuous Deployment are not just technical concepts, they’re important building blocks for creating agile, responsive, and high-quality software products. In this article, we’ll look at the key aspects and benefits of CI/CD methodologies and the role they play in the modern development cycle.
CI is the practice of automating the integration of code changes from different developers into a shared code base. With CI, conflicts, and bugs are identified and resolved early in the development cycle, minimising potential problems in the future.
While CI provides continuous code integration, CD goes further by automatically deploying successfully tested code into a live environment. This reduces the time between writing code and getting it into the hands of users, allowing teams to respond quickly to changing requirements and customer feedback.
In this article, we'll look at how these practices can help improve product quality, streamline development processes, and reduce the risks associated with updates.
What is the difference between Continuous Integration, Continuous Delivery, and Continuous Deployment?
CI is a practice in which developers integrate their code into a shared repository on an ongoing basis, usually several times a day. The main purpose of CI is to minimise the conflicts and problems that arise when code from different team members is combined.
This is done by running automated tests that help identify bugs and errors early in the development process. CI reduces the time it takes to integrate and test code, and helps maintain a stable code base.
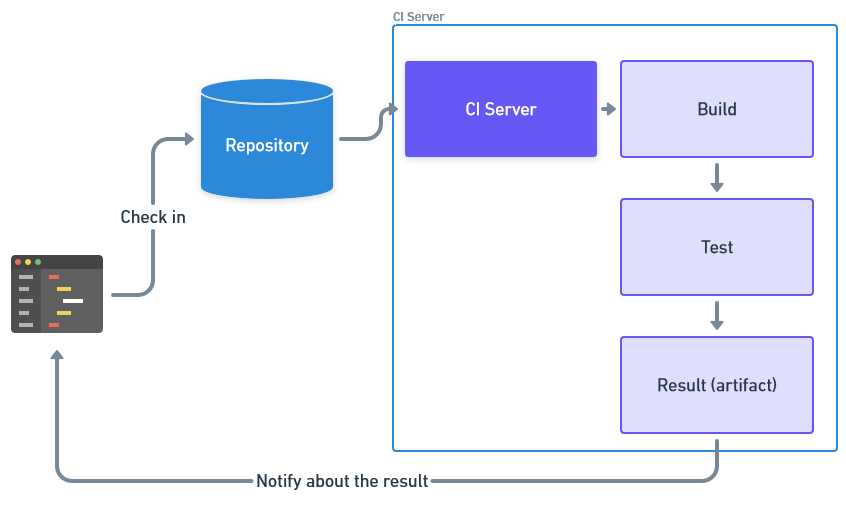
CD is the next stage after CI. It involves the automated preparation and testing of code for deployment in a live environment. During continuous delivery, the code goes through automated testing and other steps to ensure it’s ready for deployment.
However, the actual deployment to the production environment is done manually at the discretion of the team. So continuous delivery ensures code is ready for deployment at any time, but the final step requires manual intervention.
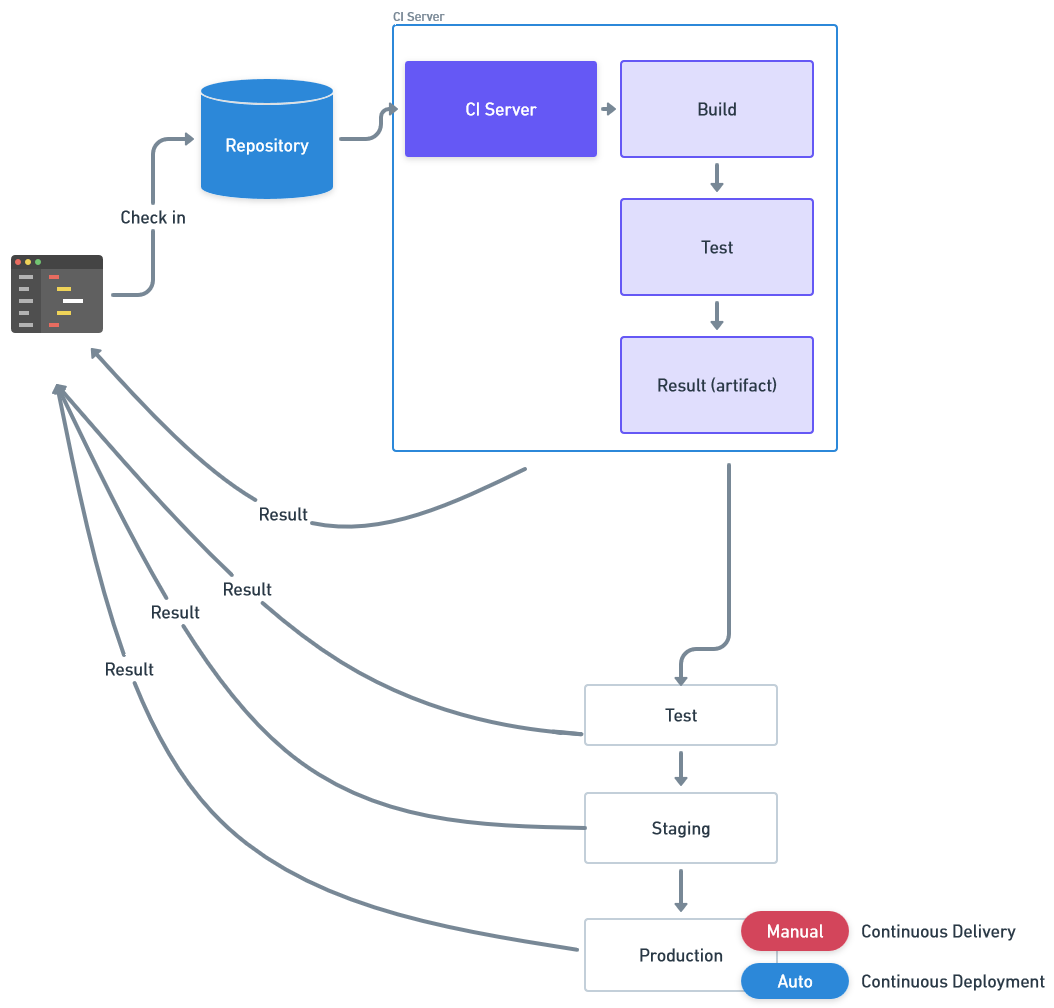
Continuous deployment goes one step further. After successfully passing all the testing steps in the continuous delivery process, code is automatically deployed into a live environment without human intervention. Each successful commit to the repository results in an automatic product update for users. Continuous deployment enables very high development speeds and ensures that new features and bug fixes can be implemented quickly.
In summary:
Continuous Integration is code integration and automated testing to detect conflicts and bugs early.
Continuous Delivery is automating code preparation for deployment and testing so that code is ready for deployment at any time.
Continuous Deployment is the automated deployment of successfully tested code into a live environment without human intervention.
The choice between these approaches depends on the company's needs and strategy.
Using some anonymised projects as examples, let's look at how the MadAppGang team implements CI/CD.
First case: Docker
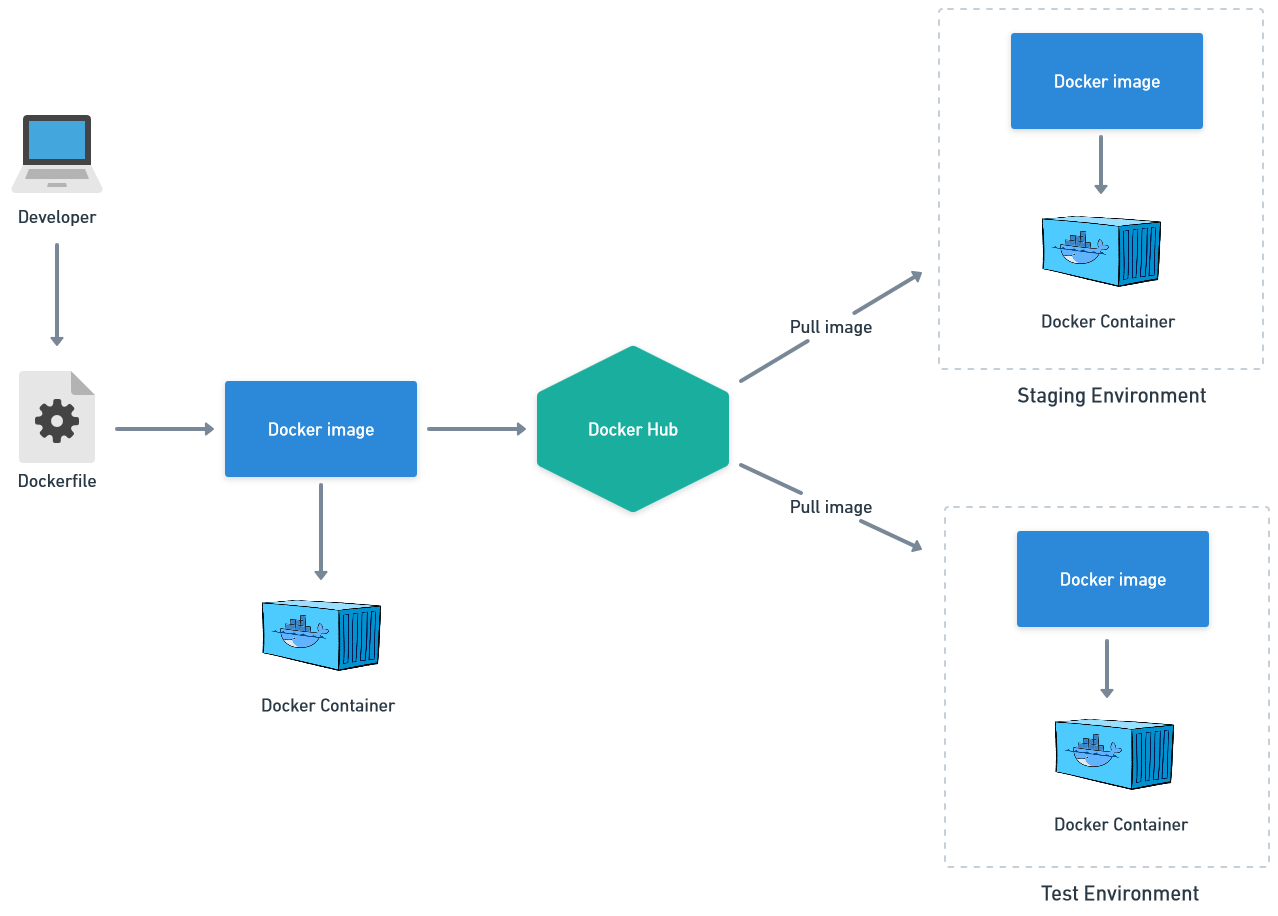
Heroku's slug and Docker build
When you submit the latest version of your code in Heroku, it automatically creates a slug, which is a package containing your application and its dependencies. During the application scaling process, this slug is downloaded and passed to a dyno for execution.
In this example, we’re using the docker build command, which is another way of creating a container image. Essentially it’s a set of instructions to go from a basic empty image to one that contains all the necessary application dependencies and the latest code.
Common goal: Containerised deployment
The goal for both Heroku and docker build is the same: start with application code and get a finished package that can be deployed in a container. The essence of the approach is similar to how we used to compile a JAR file for Java. Now, instead of a Java virtual machine, we have a containerised solution.
Although many people associate containers with Docker, they’re actually two different technologies. Docker is part of the Open Container Initiative (OCI), which includes standards for formatting container images. Also important is the container runtime, which takes container images and runs them. Docker is one of the most popular container runtimes.
However, many platforms that use containers have moved away from Docker, they’re using alternatives such as containerd. There are also alternatives for building Docker images, such as Podman.
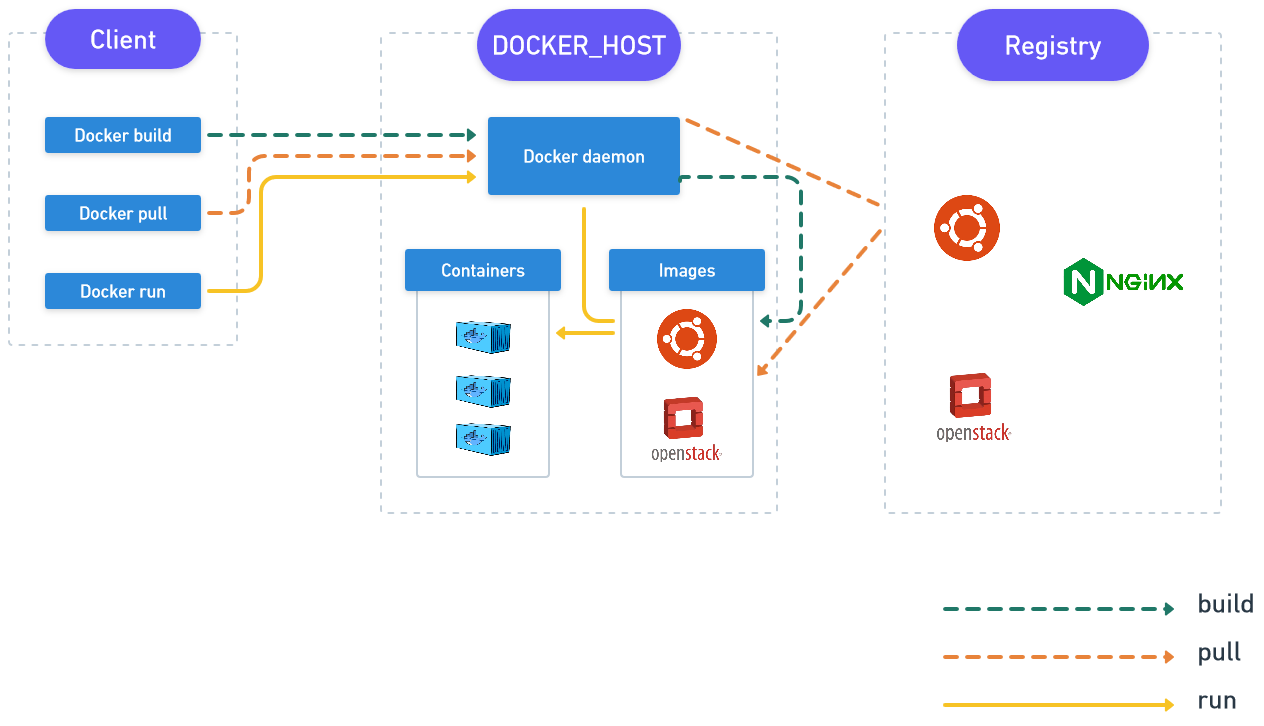
So the world of containers is much more diverse than just the docker build and docker run commands. At MadAppGang, we still use docker build, but have abandoned docker run. The concept of standardised container images is important in the industry and we remain committed to this approach.
Second case: Buildpacks
Following the same standards and working in the same environment, the industry has seen the emergence of an alternative method known as build packages, based on a concept taken from Heroku.
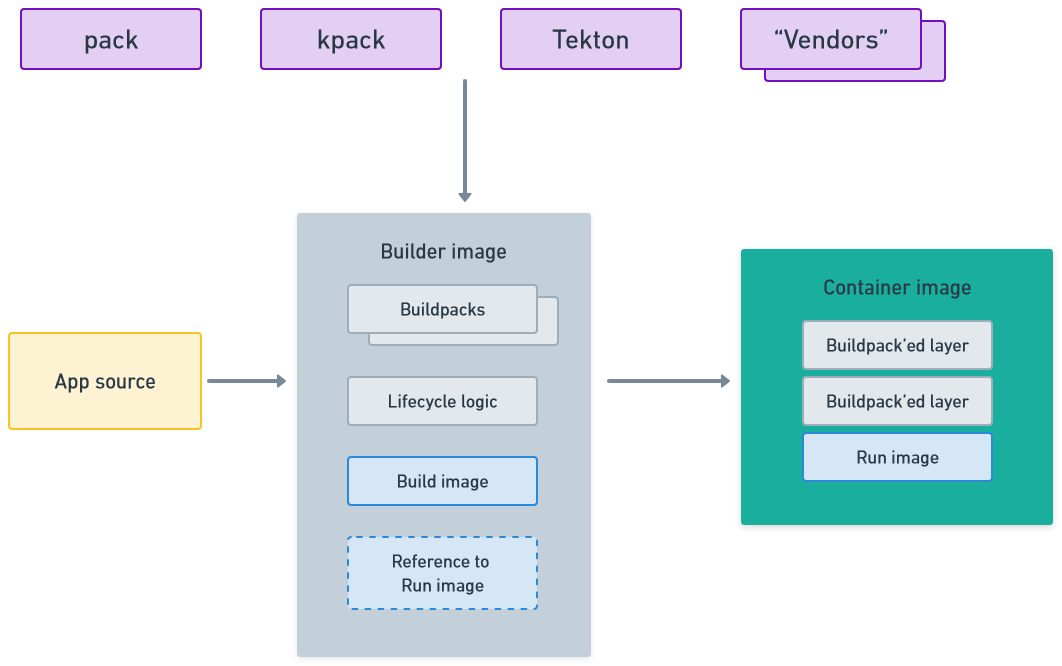
The difference between Docker and Buildpacks
Docker containers are built based on the idea of layers. You start with a base image, and then the Docker file acts as a set of instructions to add successive layers to that base image. This process creates the final image that’s later deployed in a container.
Buildpacks take a different approach: instead of working with individual layers, they use their own base archive, which acts as the root of the package. They then analyse the code and programmatically add what they need to that package.
The differences between docker build and buildpacks are small but important. For example, in Docker, caching is completely per-layer, which means that if you need to rebuild a package, you have to rebuild the entire relevant layer and reinstall all the components. This can cause caching problems. The simplification process specific to Docker can lead to situations where you encounter cached binaries, making debugging difficult.
Buildpacks, in contrast, prioritise speed and convenience over the uniformity and simplicity of layered images. Heroku has adopted the buildpack approach, and the OCI buildpack images are designed based on the Heroku buildpacks.
A buildpack is a software tool with the capability to analyse the code being pushed and subsequently transform it into an OCI image. It's equipped to manage its cache, which means that instead of performing a fresh ‘bundle install’ each time, a buildpack can maintain a cache of gems across runs. As a result, it only needs to download and install newly added gems since the last run, offering substantial efficiency.
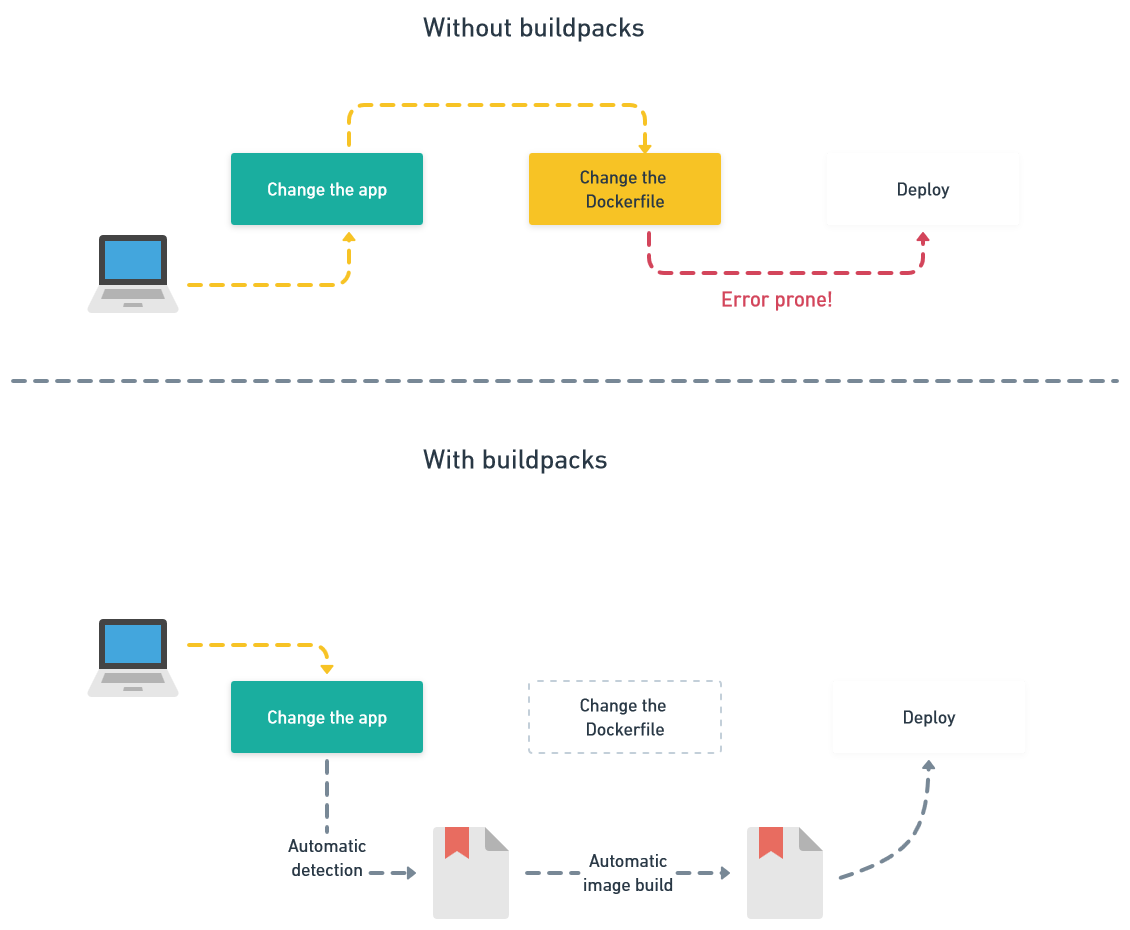
The buildpack advantages
Consider the scenario of our featured project: an Angular application with a large compilation phase. A buildpack can skilfully cache the compilation artifacts in a more substantial way than a layer cache. This is because the compilation artifacts are derived from the execution of the steps outlined in the layer instructions.
If this layer needs to be rebuilt, the entirety of its contents will disappear, mirroring the behaviour of the bundle install. However, by using a buildpack, we can preserve most of the compiled JavaScript assets, and only need to recompile files that have undergone significant changes. This refinement speeds up the process considerably.
Another benefit of buildpacks is their ease of use. Developers are used to the simplicity of git push, a workflow that integrates seamlessly with Heroku. This seamlessness is made possible by buildpacks' ability to intelligently evaluate the code they're processing.
In contrast, a Docker file is a rudimentary and unsophisticated process that simply follows a sequence of instructions for adding layers. In the absence of sophistication, some people have attempted to introduce complexity into Dockerfiles, ultimately leading to confusing results.
Buildpacks take a different perspective: they aim to relieve developers of the need to actively manage tasks such as caching dependencies or determining the embedded Ruby version. When working with a Docker file, it's imperative to explicitly specify the base image, complete with the intended Ruby version.
However, buildpacks approach this from a more intuitive angle, intelligently analysing the gemfile and attempting to infer the appropriate details. This in turn introduces a higher level of convenience.
The compromise you have to put up with
There is a trade-off between the complexity and potential reliability compromise introduced by the use of buildpacks. This is because caching dependencies between successive builds introduce a degree of interdependency between builds. Much like the consequences of failing to properly reset conditions after a test, this interdependency can cause subsequent tests to fail.
The idea that a single build has the potential to affect the results of future builds introduces an element of confusion, particularly in the context of continuous integration. Heroku has devoted significant resources to ironing out these issues within the platforms it supports. If you've worked with one of these well-established platforms, such as Ruby or Node, your experience was probably seamless.
However, if you venture beyond the boundaries of Heroku's comprehensive coverage, you may encounter idiosyncrasies where a deployment may succeed or fail due to factors unexpectedly retrieved from the cache. This may require unconventional measures, including manually flushing the Heroku slug build cache.
What developers choose
People have commonly gravitated towards the straightforward nature of Dockerfiles. Despite the appeal of their streamlined approach, Dockerfiles tend to be less user-friendly than buildpacks and generally take longer to compile.
Their simplicity does allow for a quick learning curve, though, as Dockerfiles consist of instructions similar to commands you would execute manually. This feature promotes comprehension and leaves no ambiguity about the expected outcome, as Dockerfiles lack the complicated conditional statements found in buildpacks.
Exploring cloud-native buildpacks: Enhancing compatibility and security
Beyond Heroku, there's the cloud-native buildpacks initiative known as buildpacks.io. These are similar to Heroku's approach, providing OCI container images that are compatible with Docker, containerd, or cri-o runtimes. In the context of Kubernetes, we've implemented containerd.
On Amazon's EKS (Elastic Kubernetes Service) nodes, we use an operating system called Bottlerocket, which depends on containerd. Bottlerocket is a Linux-based operating system designed for container-centric environments. It’s an open-source solution used primarily by Amazon.
The majority of prominent hosted repositories, including the one we employ (AWS's ECR), provide automated vulnerability scans for images. These scans identify potential vulnerabilities within the image's binaries (for example, an outdated version of OpenSSL that might harbour a vulnerability) and promptly issue alerts. Furthermore, you can establish policies in AWS that stop vulnerable images from entering the repository.
Various tools are available that inspect and assess whether your Dockerfile employs the latest version. It would indeed be intriguing if a tool could automatically initiate pull requests in such a manner. But seamlessly integrating Dockerfiles is challenging because no one agrees on a location for declaring these versions.

Third case: Deployment with GitHub Actions
In this section, we delve into an example involving a fulfilment application, and its deployment is facilitated by GitHub Actions.
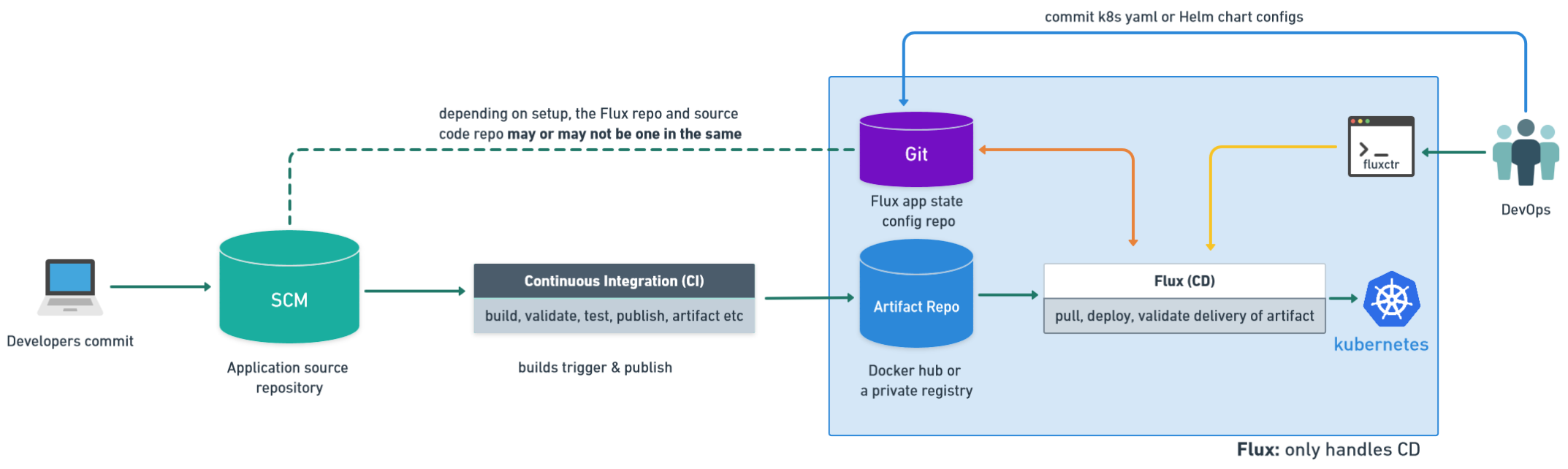
Unified workflow with Docker and ECR
The workflow implemented in GitHub Actions closely mirrors our earlier observation. It primarily revolves around Docker-based building and subsequent ECR image pushing. Notably, a key divergence lies in the CI/CD process itself. Here, the synchronisation of the docker build, image push, and cluster deployment occurs simultaneously. This signifies that the docker build exclusively pertains to PR mode, avoiding code deployment to the cluster with every PR submission.
Configuration and code segregation
An interesting parallel emerges with the Heroku approach, emphasising the clear separation between configuration and code. Drawing inspiration from our Kubernetes setup, we maintain an application repository containing code, complemented by a dedicated manifest repository focused on configuration details. This encompasses elements like environment variables, process execution specifics, arguments, scaling parameters, and more.
Such compartmentalisation is convenient because it lessens merge conflicts and other challenges during configuration modifications. In the context of the CI/CD process, this segregation necessitates the collaborative deployment of both repositories.
Streamlining workflow dispatch and enhancements
Promptly triggering the application repository deployment upon manifest repository changes needed strategic solutions. There is considerable potential to the existing workflow dispatch mechanism within the manifest repository. While our current approach employs a unified pipeline for comprehensive aspects, there's room for optimisation to differentiate between the two types of changes, minimising redundancy in workflow triggers.
Security considerations and permissions
The absence of a security framework means specific permissions have to be allocated. The necessary access rights need to be provided for seamless operations. A pivotal aspect involves enabling the deployment workflow to access the other repository.
While GitHub workflows offer access to their originating repository for code checkout, direct access to repositories within the same organisation isn't supported through UI or configuration. Instead, people need to manually create an access token, designated as a secret within the project.
This token-driven approach ensures distinct user context when engaging with the second repository. However, it introduces a critical security consideration, mandating diligent creation, maintenance, and safeguarding to prevent inadvertent leaks.
Workflow initiation and GitHub Actions
Initiating a workflow within the repository, contingent upon changes in the second repository means using a token with workflow execution permissions. But GitHub Actions currently lacks a native mechanism to facilitate this.
You can devise solutions to get around this, but these parallel situations are encountered in AWS, where leveraging a similar concept like "reading a lambda" is consistently recommended.
Balancing security and functionality
An alternative solution, akin to crafting a Personal Access Token (PAT) and leveraging the API, presents itself within the GitHub ecosystem. GitHub's documentation consistently highlights the limitations and inherent security implications of PATs, though. In light of this, it’s best to leverage applications or other feasible alternatives for enhanced security.
Despite the challenges faced, there remains optimism for the development of effective solutions. However, current trends suggest that GitHub seems committed to a one-repository workflow model, indicating potential directions for the evolution of workflows in the future.
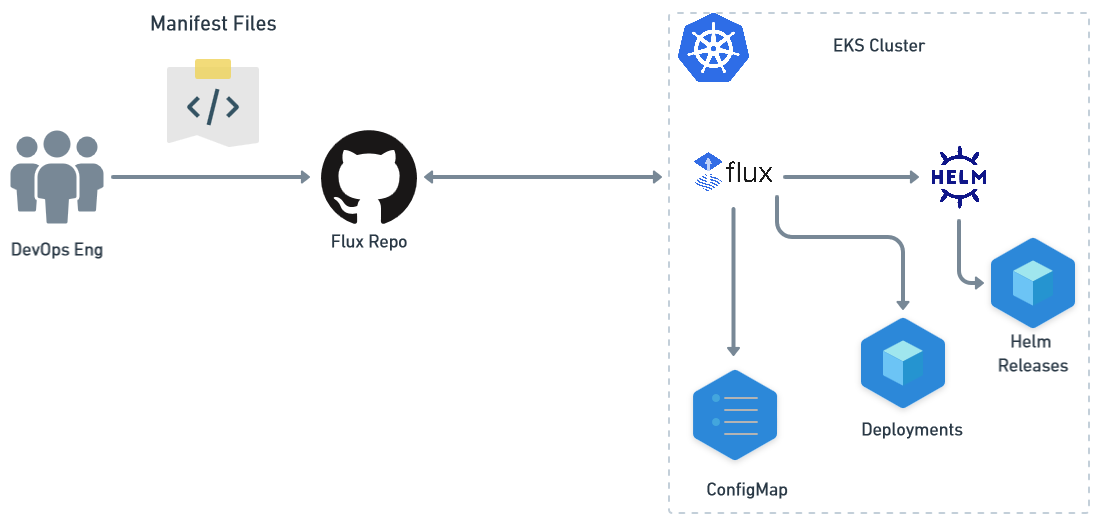
Fourth case: Integrating code and manifests in a single repository
In this instance, we explore a scenario where both the application code and the manifest definitions coexist within a single repository. The core concept is for developers to directly engage with the application repository for code modifications. Concurrently, a designated manifest directory contains the Kubernetes manifest definitions or other pertinent manifests for Kubernetes.
Streamlined workflow
With this methodology, there’s no need to trigger a separate pipeline for the manifest repository once the application code changes. In terms of workflow, the application's workflow definition and execution remain aligned, while the manifest's actions are addressed in a more intuitive manner.
Workflow execution and deployment
The initial job in the workflow encompasses building the Docker image and transmitting it to ECR. This step hinges on the application code. The subsequent job, which is responsible for EKS deployments, initiates immediately after the initial job's completion. The workflow then creates manifest files using Helm, eventually culminating in an EKS deployment, using the image generated in the initial phase.
Advantages and considerations
This approach boasts simplicity since it removes the need for permissions or tokens that grant access to a distinct repository. A potential drawback is that both developers and DevOps engineers are required to make modifications within the same repository. Tracking the origin of changes may present challenges.
On the flip side, developers actively participating in updating manifest definition files can yield benefits. Developers possess an acute understanding that altering manifest definitions is an integrated aspect, residing within the main repository. This grants them the autonomy to interact with manifest files at will. This ideology harbours both advantages and limitations, creating a distinctive dynamic.
On the other hand, there are benefits to encouraging developers to take an active role in modifying manifest definition files. Developers have a clear understanding that any changes to the manifest definition fall within the scope of the array, which is located directly in the main repository. This gives them the independence to deal with the manifest files as they see fit. As such, it reflects a particular philosophy, which has both strengths and weaknesses.
Challenges and engagement
There’s further complexity when changes to manifest files mean pushing merged code changes into the main branch, even if they aren't yet ready for deployment. This diverges from the Twelve-Factor App concept of segregating code from the configuration.
Nonetheless, the appeal of having the manifest closely aligned with the application code lies in its simplicity and its proximity to developers. This shift, albeit small, heightens the likelihood of developer involvement.
Testing with Helm
Observing this approach firsthand underscores its efficacy in helping developers add new environment variables or secrets, prompting their willingness to contribute. A subsequent review request from the DevOps team streamlines the process.
In contrast, other strategies that involve changes in a separate manifest repository tend to entail steeper learning curves and perceived leaps. The separation can foster a sense of being outside one's domain. However, the method of retaining manifests within the app repository transforms the interaction dynamic, akin to stepping into a shared environment, fostering collaboration and engagement.
Enhancing Helm with tests
Before the next example, here’s a closer look at our approach to testing Helm, the tool instrumental in generating manifest files for this project.
By feeding sample values into the Helm chart, we validate the generated manifests, ensuring correct configuration. In numerous applications, we've integrated kustomize, a tool enabling structural alterations to Kubernetes manifests. Our experience with Helm showcases its efficiency in facilitating simple template construction across various environments. A single values file, rather than multiple folders, simplifies the process and enhances consistency.
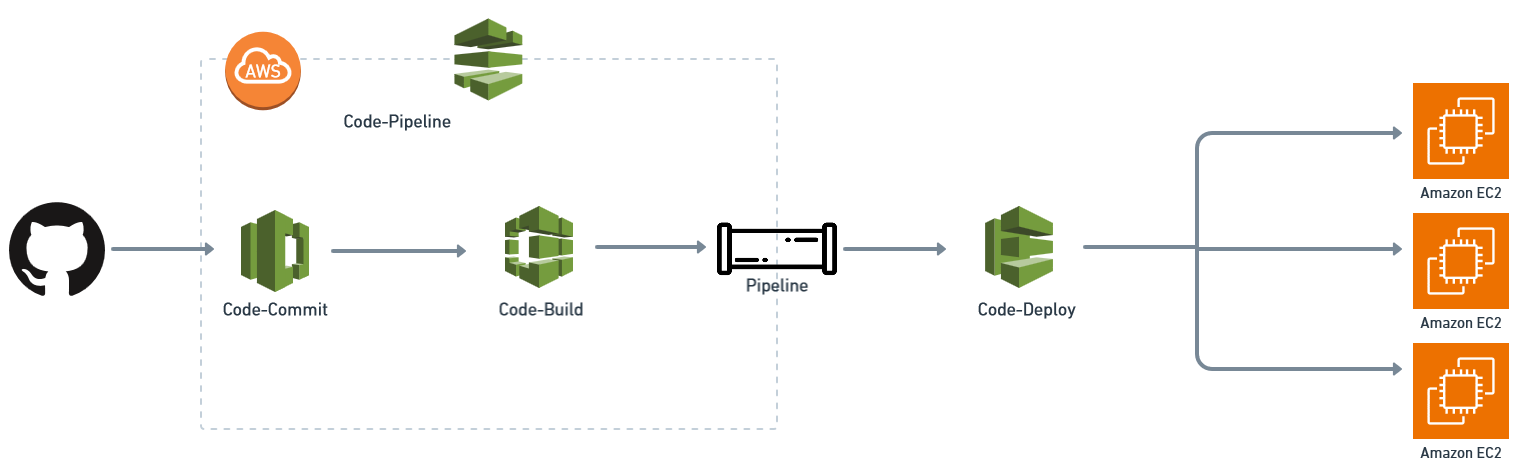
Fifth case: Leveraging AWS's CodeBuild and CodePipeline
In this example, we delve into an alternative strategy that harnesses AWS's CodeBuild and CodePipeline. This approach, used as our illustration and previously employed extensively before transitioning to GitHub Actions, capitalises on the seamless integration of CodeBuild and CodePipeline. These services collaborate to orchestrate a series of steps triggered by code changes.
Workflow and environment
CodePipeline orchestrates the workflow, while CodeBuild provides the execution environment for these steps. The analogy to GitHub Actions is evident: a workflow versus a job. CodePipeline’s notable feature is its proficiency managing multi-repository workflows, a trait that sets it apart.
Streamlined management of repositories
CodePipeline offers the functionality to declare multiple sources for a pipeline, diligently monitoring the latest versions of each repository. Upon changes in either repository, the pipeline engages with the latest iterations of both. This mechanism renders the workflow transparent, particularly concerning the separate source and manifest repositories, offering visibility into altered versions.
Build and deployment phases
The subsequent build phase is distinguished by the segregation of projects for manifest and application code. The deployment phase amalgamates these components. This approach streamlines both the presentation and execution facets, in contrast to GitHub Actions’ cross-repository method.
Enhanced management and infrastructure integration
An advantage of this approach is simplified repository-access management. Being able to specify pipelines' repository access removes the need for one repository to trigger a workflow in another. CodePipeline operates beyond repository confines, making up a key part of the infrastructure.
Comparative reflection and complexity
The concept of having a similar feature in GitHub is appealing, yet it’s worth noting that using GitHub Actions offers a more straightforward process that mitigates complexity. Additionally, it gives developers direct access to the CI/CD process, enhancing efficiency and engagement.
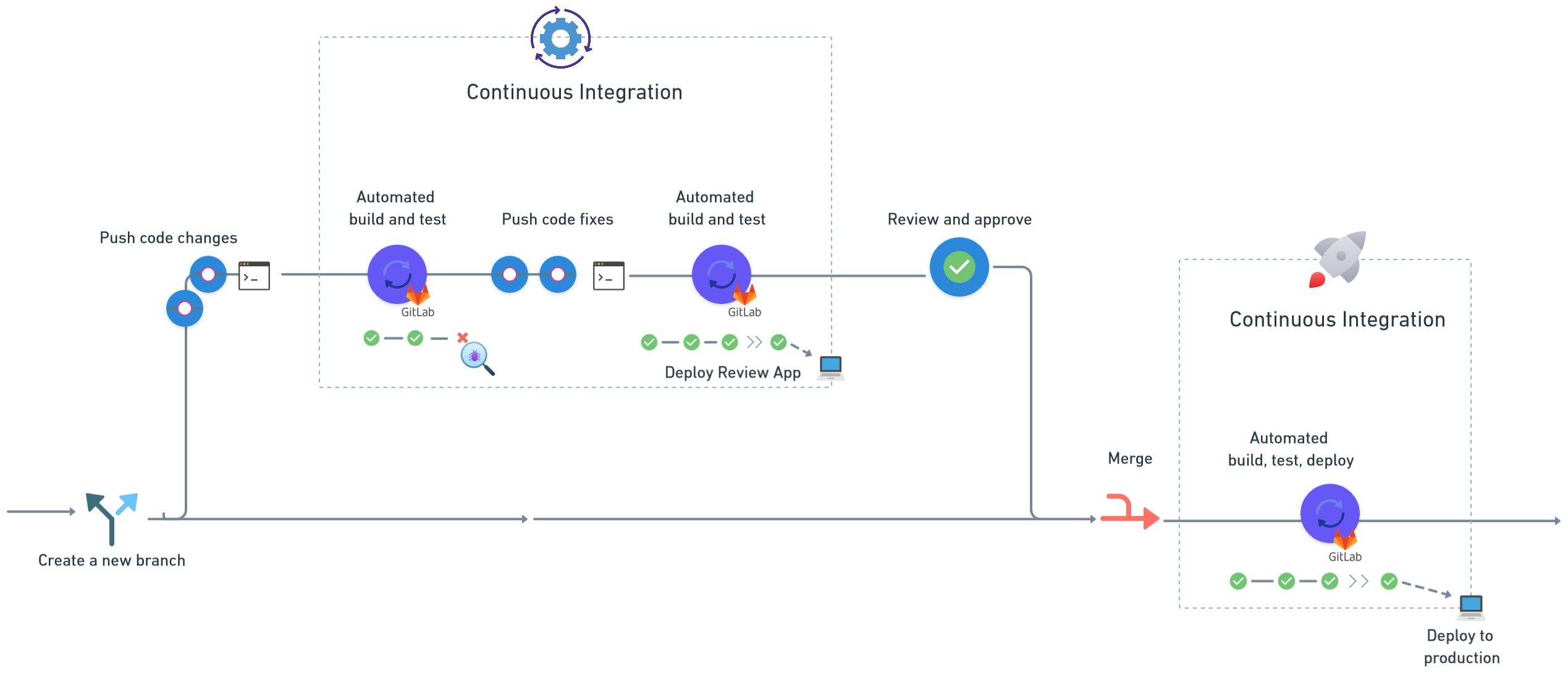
Sixth case: Harnessing GitLab
In this final scenario, we'll delve into an alternative method that leverages GitLab's CI/CD capabilities. Just as in the preceding examples, we'll explore how this platform facilitates streamlined development, continuous integration, and efficient deployment practices.
GitLab CI/CD functions as a comprehensive platform, seamlessly integrating with your code repositories and streamlining the development lifecycle. Similar to other platforms we've discussed, GitLab CI/CD enables the creation of workflows that automate processes and respond to code changes.
Workflow setup and execution
Developers interact with the application repository, making code changes and updates. GitLab CI/CD is configured to react to these changes, initiating a series of predefined actions. The platform executes jobs within a specified environment, ensuring consistency and reliability in the build and deployment process.
Code testing and compilation
As part of the workflow, GitLab CI/CD performs essential tasks such as code testing, validation, and compilation. This guarantees the integrity of the codebase and identifies potential issues early in the development process. The platform supports a variety of programming languages and tools, accommodating diverse project requirements.
Multi-Repository coordination
Just as AWS's CodePipeline skillfully manages multi-repository workflows, GitLab CI/CD coordinates actions across multiple repositories. Changes in interconnected repositories are synchronised and executed in a coherent manner.
Simplified access management
GitLab CI/CD offers built-in repository-access management, simplifying the process of granting permissions and controlling access to different stages of the CI/CD pipeline. This helps maintain security while providing an intuitive approach to managing deployment workflows.
GitLab Runner and environment
GitLab CI/CD uses a component called the GitLab Runner to execute jobs within specified environments. The Runner ensures that jobs are executed in a controlled and isolated environment, enhancing the consistency and reliability of the CI/CD process.
Advantages and comparisons
While the GitLab CI/CD approach aligns with platforms like GitHub Actions and AWS's CodePipeline in terms of workflow automation, it also brings unique advantages. GitLab's integrated ecosystem, repository management, and robust CI/CD capabilities offer a compelling solution when a project demands streamlined development processes.
In summary, GitLab CI/CD presents an effective alternative for managing code, automating workflows, and optimising deployment practices. Just as in the examples of Docker, Buildpacks, GitHub Actions, CodeBuild, and CodePipeline, GitLab CI/CD enables developers to achieve efficient continuous integration and deployment within their projects.

